デバイス監視ログ可視化システム(version 2.7以降)¶
概要¶
デバイス監視ログ可視化システムは、各デバイスの監視ログの登録を行うデバイス監視ログ収集サーバー、 監視ログを保存するデバイス監視ログ収集データベース(Elasticsearch)、 保存された監視ログを可視化するデバイス監視ログ可視化ツール(Grafana)から構成される。
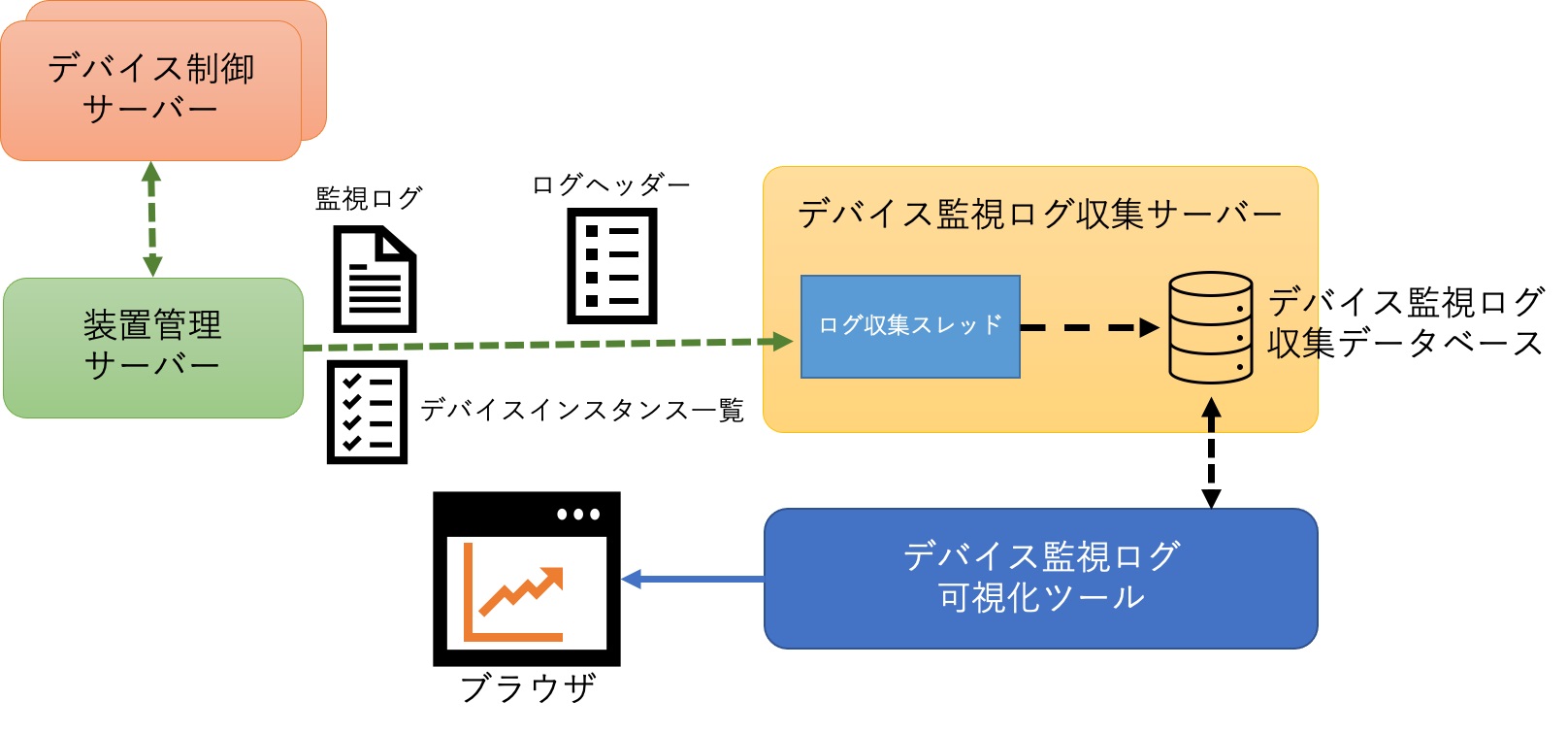
Fig. 314 デバイス監視ログ可視化システムの概略図¶
ElasticsearchおよびGrafanaはDockerを用いずに直接インストール・起動する方法(a)と、 Dockerコンテナ上で起動する方法(b)がある。
Note
デバイス監視ログ収集サーバーはElasticsearch7に対応している。 2026年4月時点(IROHA2.11)ではElasticsearch8以上もしくはOpenSearchへの対応はできていない。
a.1. Elasticsearchの導入¶
Dockerを用いずにElasticsearchを計算機に直接インストールして起動する方法について説明する。
インストール¶
Elasticsearchに依存しているパッケージをインストールする。
$ sudo yum install java-11-openjdk
Elasticsearchソフト用の公開鍵をインストールする。
$ sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
/etc/yum.repos.d/elasticsearch.repo を作成し、以下を書き込む。
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
Elasticsearchをインストールする。
$ sudo yum install --enablerepo=elasticsearch elasticsearch
設定¶
Elasticsearchの設定ファイル /etc/elasticsearch/elasticsearch.yml の修正を行う。
# 23行目を修正し、ノード名にホストの名称を設定する。
node.name: iroha2
# 56行目を修正し、外部ホストからの接続を許可する。
network.host: 0.0.0.0
# 70行目を修正して外部ネットワーク接続用のIPのアドレスを設定し、自ホストが検索できるようにする。
# ここでは、例としてIPアドレスを192.168.0.10とする。
discovery.seed_hosts: ["192.168.0.10"]
# 74行目を修正し、マスターノードを指定する。
# ノード名は、23行目に指定したnode.nameを使用する。
cluster.initial_master_nodes: ["iroha2"]
# ファイル末尾に以下を追加し、セキュリティ設定を有効にする。
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
起動¶
systemctlコマンドでElasticsearchを起動する。
# Elasticsaerchのsystemctlへの登録(初回のみ)
$ sudo systemctl daemon-reload
# Elasticsearchの自動起動を有効化する場合
$ sudo systemctl enable elasticsearch
# Elasticsearchの起動(数10秒かかる)
$ sudo systemctl start elasticsearch
パスワードの設定¶
以下のコマンドを実行し、対話形式でパスワードの設定を行う。 複数回パスワードを聞かれるが、すべて同じパスワードを入力すればよい。 この説明では例としてパスワードを mlfadmin に設定する。
$ sudo /usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
Roleとユーザーの設定¶
Elasticsearchのインデックスに対する書き込み、読み取りを制限するためのRoleを設定する。
書き込み用Role¶
装置コードABCのすべてのインデックス(logsurv*abc)に対するすべての権限を持つRoleとして bl00all を追加する場合、以下のコマンドを実行する (Elasticsearchのパスワードが mlfadmin の場合)。
$ curl -XPOST -u elastic:mlfadmin -H 'Content-Type:application/json' localhost:9200/_security/role/bl00all -d '{
"indices" : [ {
"names" : [ "logsurv*abc" ],
"privileges" : [ "all" ] }
] }'
このRoleに属するユーザーとして bl00 (パスワード bl00user )を追加する場合、以下のコマンドを実行する (パスワードの設定 で設定したElasticsearchのパスワードが mlfadmin の場合)。
$ curl -XPOST -u elastic:mlfadmin -H 'Content-Type: application/json' localhost:9200/_security/user/bl00 -d '{
"password" : "bl00user",
"full_name" : "bl00 user",
"roles" : "bl00all"
}'
このユーザー bl00 は、デバイス監視ログ収集サーバーが装置管理サーバーから収集した情報をElasticsearchに書き込むために必要となる。 また、Grafanaのデータソースを指定する際にこのユーザーを利用することで、Roleで定めた範囲のインデックス(logsurv*abc)をすべて表示させることができる。
読み取り専用Role¶
あるインデックスに対して読み取りのみ可能なRoleを設定する場合には、privilegesを[“read”, “view_index_metadata”]にしてコマンドを実行する。 例えば、装置コードABCのあるデバイス(例としてFastDouble)のインデックス(logsurvfastdouble-abc)に対する読み取りの権限を持つRoleとして bl00fastbouble を追加する場合、以下のコマンドを実行する (パスワードの設定 で設定したElasticsearchのパスワードが mlfadmin の場合)。
$ curl -XPOST -u elastic:mlfadmin -H 'Content-Type:application/json' localhost:9200/_security/role/bl00fastbouble -d '{
"indices" : [ {
"names" : [ "logsurvfastdouble-abc" ],
"privileges" : [ "read", "view_index_metadata" ] }
] }'
このRoleに属するユーザーの追加方法は、書き込み用Roleの場合と同様である。
このユーザー bl00fastbouble は、Grafanaのデータソースを指定する際に利用する。 このユーザーで指定したデータソースからは、Roleで定めた範囲のインデックス(logsurvfastdouble-abc)のみが表示できるようになる。
Note
バージョン2.8.2以前には device-log-gathering-server/utility にRoleおよびユーザーを
作成( create_role.py 、 create_user.py )、
削除( delete_role.py 、 delete_user.py )、
表示( ls_role.py 、 ls_user.py )
するためのPythonスクリプトの例が用意されており、これらを編集することで上記の操作が可能である。
バージョン2.8.3以降はこれらのスクリプトを util/elasticsearch/ に移動し、コマンドライン引数で種々の設定を行うことができるように改良を行った。
a.2. Grafanaの導入¶
Dockerを用いずにGrafanaを計算機に直接インストールして起動する方法について説明する。
インストール¶
Grafanaに依存しているパッケージをインストールする。
$ sudo yum install urw-fonts
Grafanaのパッケージを取得する。
$ wget https://dl.grafana.com/oss/release/grafana-8.3.1-1.x86_64.rpm
取得したGrafanaのパッケージをインストールする。
$ sudo rpm -ivh grafana-8.3.1-1.x86_64.rpm
Note
Grafanaのバージョンは8または9を選択する。
起動¶
systemctlコマンドでGrafanaを起動する。
# Grafanaのsystemctlへの登録(初回のみ)
$ sudo systemctl daemon-reload
# Grafanaの自動起動を有効化する場合
$ sudo systemctl enable grafana-server
# Grafanaの起動
$ sudo systemctl start grafana-server
b. DockerによるElasticsearchとGrafanaの起動¶
計算機にElasticsearchおよびGrafanaを直接インストールして起動するのではなく、 Dockerコンテナ上でElasticsearchおよびGrafanaを起動する方法について説明する。 なお、Dockerのインストールや設定についての説明は省略する。
docker-compose.ymlの編集¶
ディレクトリ /opt/mlfsoft/iroha2/device-log-gathering-server/docker に移動し、
docker-compose.yml に記述されている設定を必要に応じて変更する。
項番 |
設定項目 |
説明 |
デフォルト値 |
|---|---|---|---|
1 |
services:es01:container_name |
Elasticsearchのコンテナ名 |
elasticsearch_es01 |
2 |
services:grafana:container_name |
Grafanaのコンテナ名 |
grafana_grafana |
3 |
services:es01:environment-ELASTIC_PASSWORD: |
Elasticsearchの管理者パスワード |
mlfadmin |
4 |
services:es01:volumes |
Elasticsearchのボリューム設定 |
es-data:/usr/share/elasticsearch/data |
5 |
services:grafana:volumes |
Grafanaのボリューム設定 |
grafana-data:/var/lib/grafana |
コンテナの作成・起動¶
ディレクトリ /opt/mlfsoft/iroha2/device-log-gathering-server/docker において以下のコマンドを実行する。
$ docker compose up -d
Elasticsearchの設定¶
a.1. Elasticsearchの導入 で説明したネットワークやパスワードに関する設定は不要である。 Roleやユーザーの作成は Roleとユーザーの設定 を参照のこと。
デバイス監視ログ収集サーバーの導入¶
インストール¶
デバイス監視ログ収集サーバーのソースファイル device-log-gathering-server は
IROHA2サーバー群のソースコードに含まれており、 他サーバーのソースコードと同じディレクトリに配置される。
実行に必要なパッケージをインストールする。
$ sudo yum install python3-devel
デバイス監視ログ収集サーバーでは多くのライブラリが必要になるため、 pyenvやvirtualenvなどのPythonの仮想環境を構築してそこにライブラリをインストールする。 以下、virtualenvを用いた環境構築の例を示す。
$ sudo pip3 install virtualenv
$ mkdir $HOME/.virtualenvs
$ python3 -m virtualenv -p python3 $HOME/.virtualenvs/r3iroha2_p3
$ source $HOME/.virtualenvs/r3iroha2_p3/bin/activate
# 以下、仮想環境が有効な状態
$ cd /opt/mlfsoft/iroha2/device-log-gathering-server
$ pip install -r requrements.txt
Note
バージョン2.8以降では、 iroha2/requirements.txt に
デバイス監視ログ収集サーバーの動作に必要なライブラリも含め記述されている。
設定¶
設定ファイルを実行環境に合わせて変更する。
設定ファイルは、バージョン2.9までは device-log-gathering-server/settings_app.py 、
バージョン2.10以降では iroha-settings/device-log-gathering/settings_app.json である。
項番 |
項目名 |
説明 |
デフォルト値 |
|---|---|---|---|
1 |
periodic_task_duration |
監視ログ収集間隔(秒) |
300 |
2 |
mng_srv_host |
装置管理サーバーIPアドレス |
127.0.0.1 |
3 |
mng_srv_port |
装置管理サーバーポート番号 |
8086 |
4 |
mng_srv_user |
装置管理サーバーユーザー名 |
admin |
5 |
mng_srv_password |
装置管理サーバーパスワード |
mlfadmin |
6 |
elastic_srv_url |
Elasticsearchサーバー接続URL |
|
7 |
elastic_srv_user |
Elasticsearchの書き込み用Roleに属するユーザー名 |
bl00 |
8 |
elastic_srv_password |
Elasticsearchの書き込み用Roleに属するユーザーのパスワード |
bl00user |
9 |
inst_code |
装置コード |
ABC |
10 |
num_of_jobs |
ログ収集ジョブの数 |
10 |
11 |
log_level |
ログレベル |
DEBUG |
12 |
time_zone |
タイムゾーン |
Asia/Tokyo |
13 |
collection_start_time |
ログ収集開始日時(バージョン2.10以降) |
2025-01-09 20:00:00 |
14 |
extra_days |
余裕日数(バージョン2.10以降) |
1 |
Note
バージョン2.9以下の settings_app.py の場合、項目名は大文字である。
Note
elastic_srv_userおよびelastic_srv_passwordは Roleとユーザーの設定 において設定した、 書き込み用Roleに属するユーザーのユーザー名とパスワードである
Note
デバイス監視ログファイルには、そのファイル名から取得した日付よりも新しい日付のログが含まれている可能性がある。 そのため、collection_start_timeで設定した日時よりもextra_daysだけ過去のログファイルからログの収集を行う。
起動¶
サービス起動用スクリプトを登録する。
$ sudo cp loggathsrv.service /etc/systemd/system
$ sudo systemctl daemon-reload
サーバーを起動する。
# サーバーの自動起動を有効化する場合
$ sudo systemctl enable loggathsrv
# サーバーの起動
$ sudo systemctl start loggathsrv
サーバー起動後、Webブラウザで http://localhost:8080 にアクセスすると デバイス監視ログ収集サーバーのWeb UIを開くことができる。
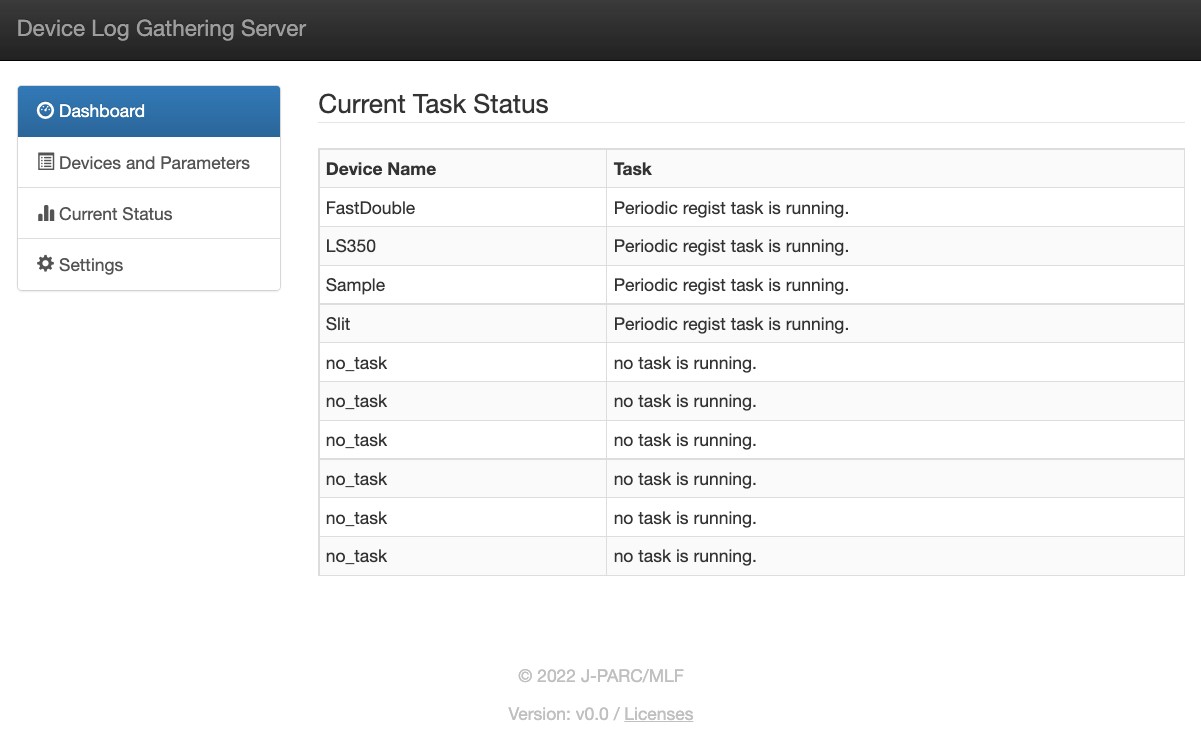
Fig. 315 デバイス監視ログ可視化サーバーのWeb UI(ダッシュボード)¶
Web UIは4つのメニューで構成され、それぞれデバイス監視ログ収集サーバーに関する情報を閲覧できる。
Dashboard画面¶
Dashboard画面には、登録されているデバイス名とタスクの状態が表示される。
Devices and Parameters画面¶
Devices and Parameters画面には、登録されているデバイス名とそのパラメータ名の一覧が表示される。
Current Status画面¶
Current Status画面には、デバイス名とそのインデックス名、 Elasticsearchに登録されているログの数、その最新日時が表示される。
Settings画面¶
Settings画面では、サーバー設定ファイルに登録されている設定の一覧を見ることができる。
Grafanaの操作方法¶
データソースの追加¶
ブラウザからGrafanaのWeb UIにアクセスする。 例としてGrafanaが192.168.0.10にインストールされている場合は、以下のURLにアクセスする。
管理者アカウントの情報(ユーザー:admin、パスワード:admin)を入力し、 Login ボタンを押下する。 画面遷移後、adminの新しいパスワードを入力する画面になるが、変更しない場合は Skip を押下する。
メニューから、 を選択し、Elasticsearchへの接続情報を追加する。 例として、Elasticsearchが192.168.0.11にインストールされており、 Roleとユーザーの設定 で例に挙げたユーザー bl00 がElasticsearchにおいて設定されているものとする。
項番 |
名称 |
設定 |
説明 |
|---|---|---|---|
1 |
Name |
BL00 |
接続名称 |
2 |
URL |
localhost:9200 |
Elasticsearch接続URL |
3 |
Basic Auth |
(選択する) |
Basic Authを使用する設定 |
4 |
User |
bl00 |
認証ユーザー名 |
5 |
Password |
bl00user |
認証パスワード |
6 |
Index name |
logsurv*abc |
インデックス名 |
7 |
Pattern |
No pattern |
パターン設定 |
8 |
Time field Name |
Date |
Timeフィールド名 |
9 |
Version |
7.10+ |
Elasticsearchのバージョン |
Note
Elasticsearchにおいて複数のRole/Userを設定している場合、Data sourcesは複数設定することが可能である。
Dashboardの作成¶
数値データのグラフ作成¶
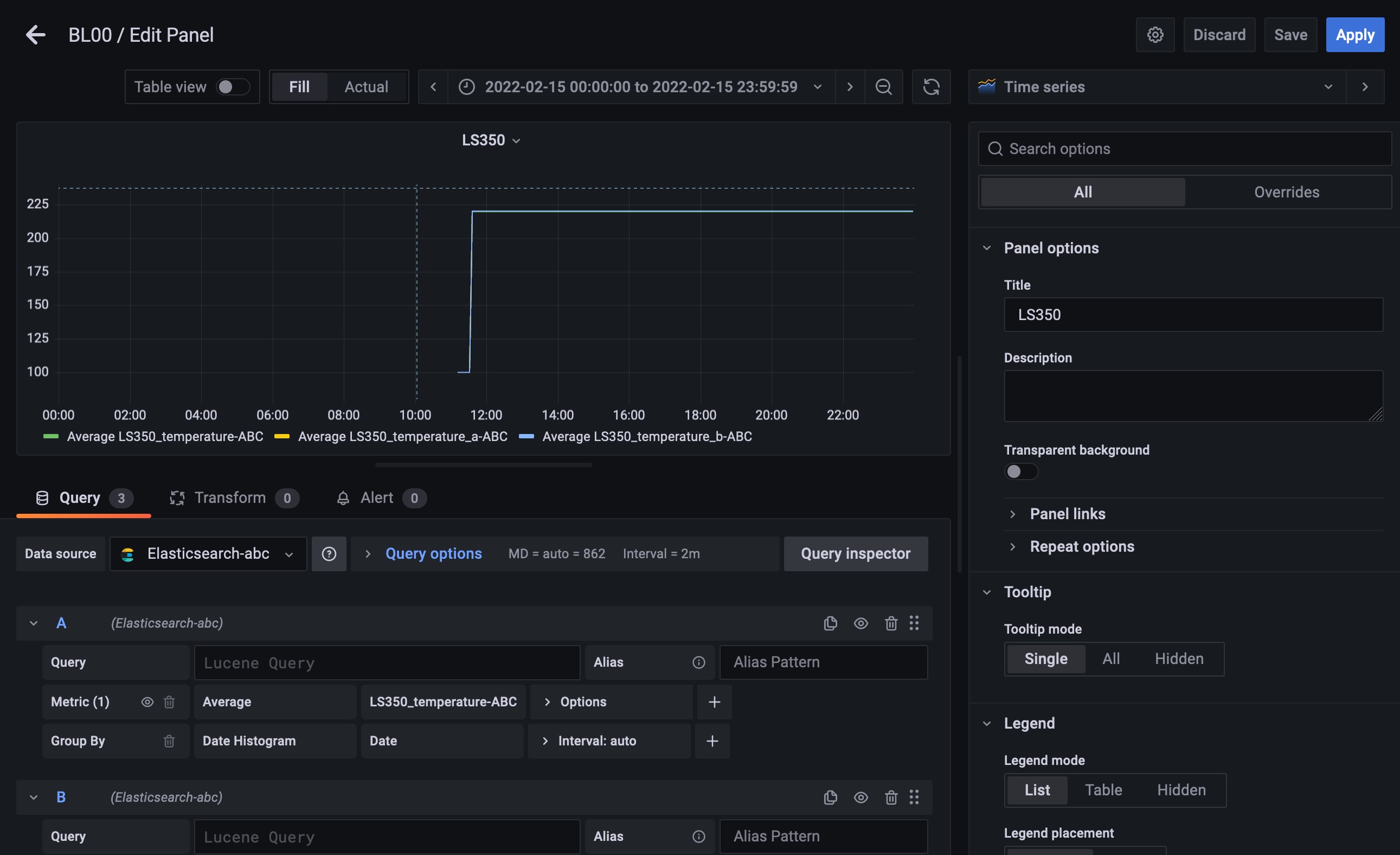
Fig. 316 数値データのグラフ設定¶
ブラウザからGrafanaのWeb UIにアクセスする
メニューの + ボタンを押下し、 を選択する
Data sourceが複数設定されている場合は選択する
Metricとして、Average・Sum・Max・Minなどから最適なものを選択する(通常はAverage)
Field名へ抽出するField名を選択する
Queryを追加するため、 +Query ボタンを押下する
表示する数値データの分だけ、4〜5を繰り返す
画面右側の列の を変更し、Panelのタイトルを設定する
画面右上の Save ボタンを押下し、Dashboard名、Folder名を設定する
画面右上の Apply ボタンを押下し、Dashboardに戻る
更にPanelを追加する場合は、画面右上のアイコン群の一番左の Add Panel を押下後、 Add a new panel を選択し、3〜10を繰り返す
最後にDashboard上で右上のアイコン群から Save を押下し保存する
Note
Field名は、以下の命名規則で構成されている。
<デバイスインスタンス名>_<パラメータ名>-<装置コード>
例えば、装置コードABCのデバイスインスタンス名LS350のパラメータtemperature_aのField名は、 LS350_temparature_a-ABCとなる。
文字列データのグラフ作成¶
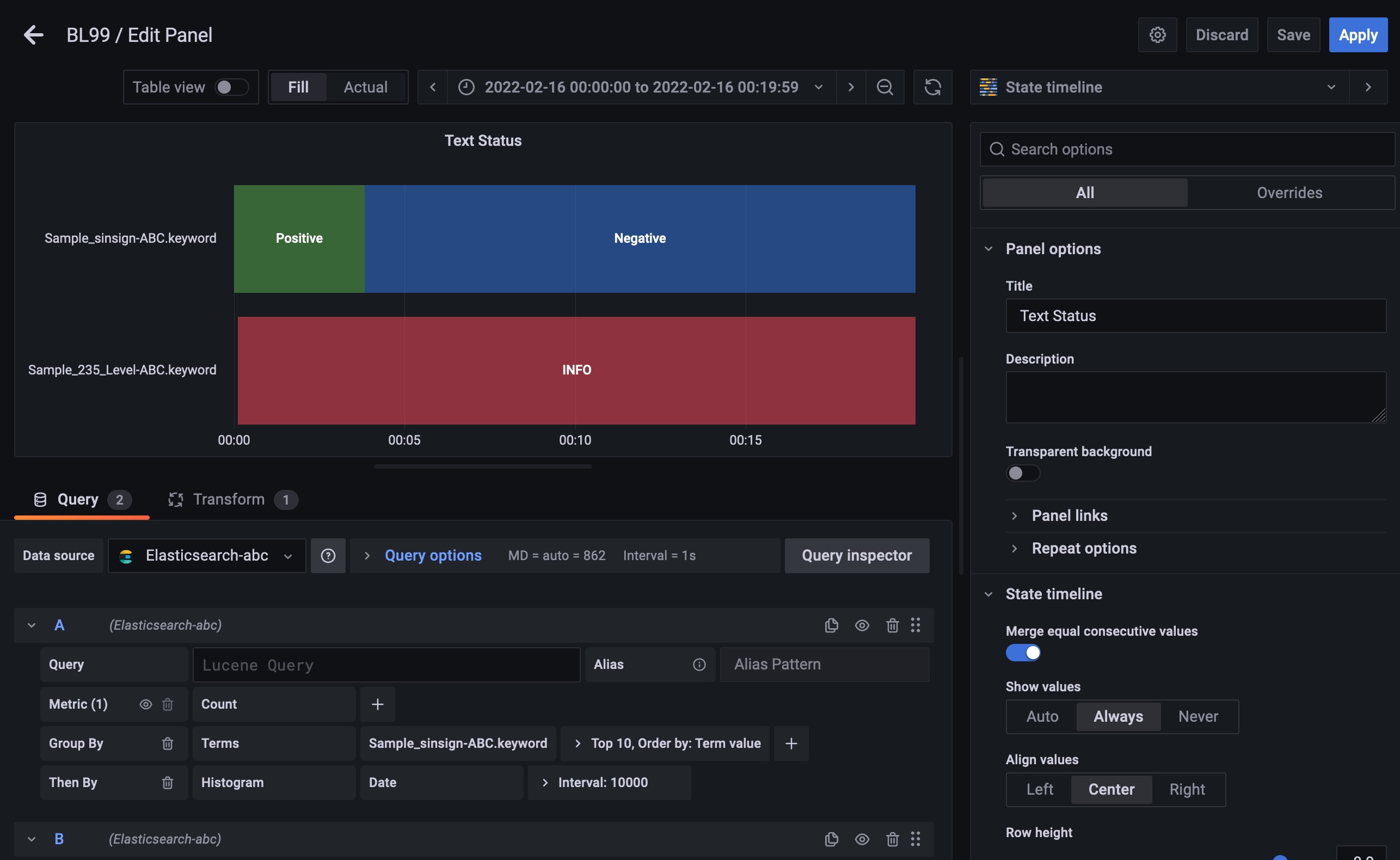
Fig. 317 文字列データのグラフ設定¶
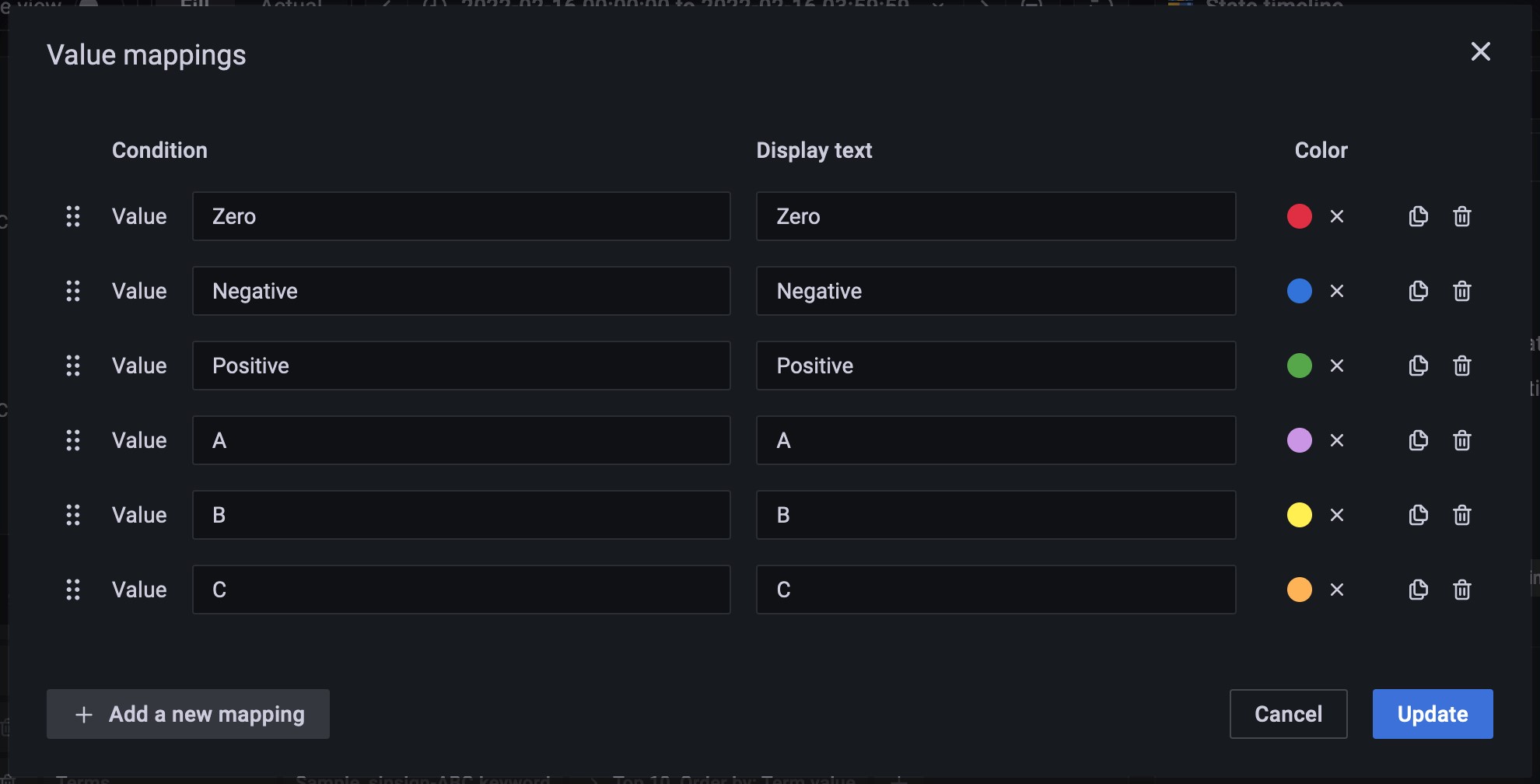
Fig. 318 Value mappingの設定¶
ブラウザからGrafanaのWeb UIにアクセスする
メニューの + ボタンを押下し、 を選択する。または、既存のDashboardで画面右上のアイコン群の一番左の Add Panel を押下後、 Add a new panel を選択する。
画面右上のPanel種別選択部分で State timeline を選択する
Data sourceが複数設定されている場合は選択する
Group Byとして Terms を選択する
Field名へ抽出するField名を選択する。このとき、末尾に.keywordと付いているものを選択する。
Group Byの右端にある + を押下する
Then Byとして Histogram を選択する
Field名として Date を入力する
Interval:~、Min Doc Count:~を展開し、Min Doc Countの値を 1 に設定する
Queryを追加するため、 +Query ボタンを押下する
表示する文字列データの分だけ、5〜9を繰り返す
画面右側の列のMerge equal consecutive valuesを On に、Line widthを 1 に設定する
画面右側の列のAdd value mappingsを選択してValue mappingsダイアログを開き、Valueへ値となる文字列とその表示文字列、色を入力する
画面右側の列のThresholdsにおいて、Base以外のThresholdを削除する
画面右側のQueryの隣の Transform をクリックする
一覧から Filter by name を選択し、表示された項目から、 Count のチェックを外す
画面右側の列の を変更し、Panelのタイトルを設定する
画面右上の Save ボタンを押下し、必要に応じDashboard名、Folder名を設定する
画面右上の Apply ボタンを押下し、Dashboardに戻る
更にPanelを追加する場合は、画面右上のアイコン群の一番左の Add Panel を押下後、 Add a new panel を選択し、3〜18を繰り返す
最後に、Dashboard上で右上のアイコン群から Save を押下し保存する
Note
Field名は、以下の命名規則で構成されている。
<デバイスインスタンス名>_<パラメータ名>-<装置コード>
例えば、装置コードABCのデバイスインスタンス名LS350のパラメータsensorの「.keyword」付きField名は、 LS350_sensor-ABC.keywordとなる。
ユーザーの追加¶
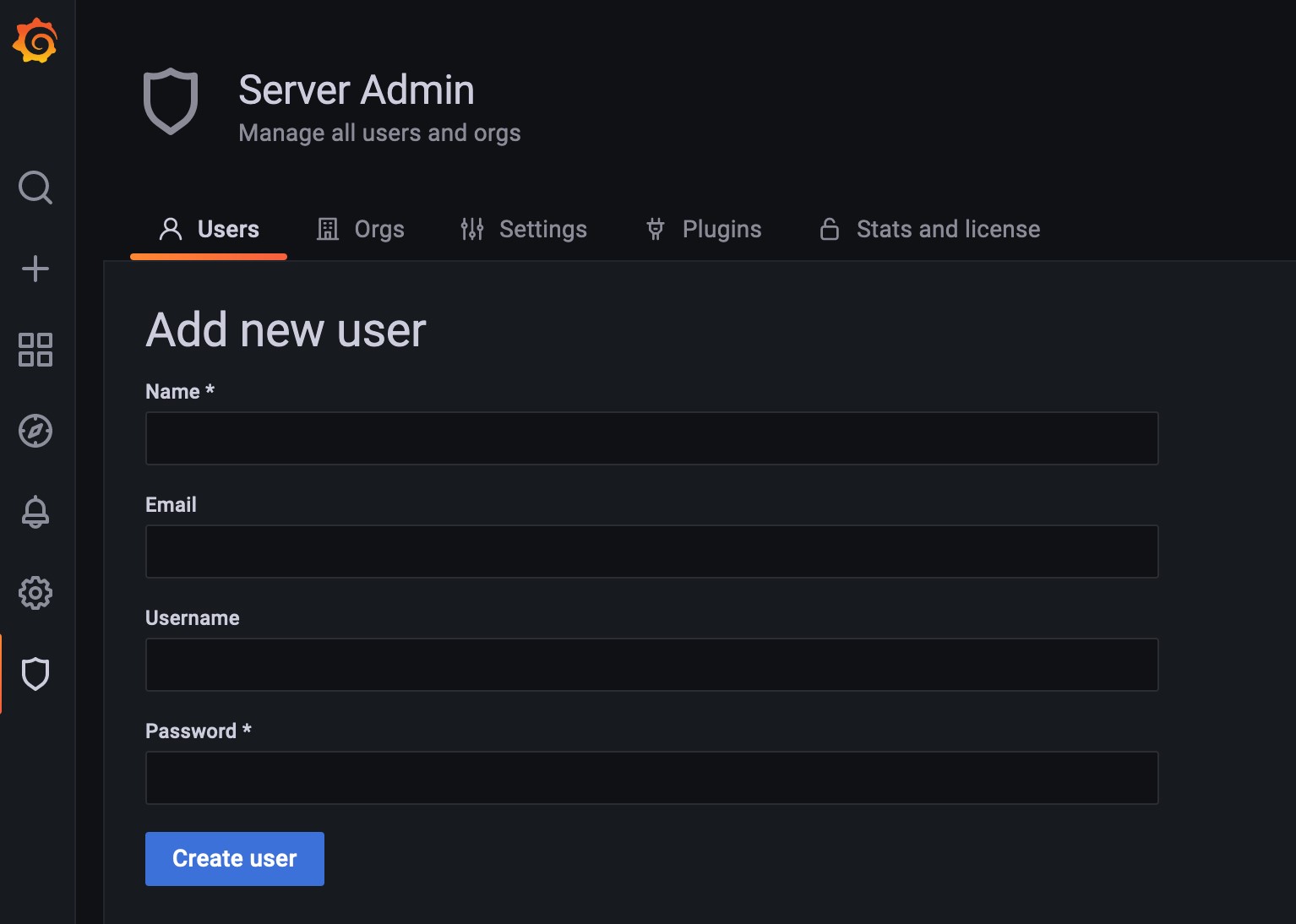
Fig. 319 ユーザー追加画面¶
ブラウザからadminユーザーとしてGrafana Web UIへログインする
メニューから、 を選択する
New user を押下し、必要項目を入力後、 Create user を押下する
ユーザーのRoleはデフォルトでは Viewer なので、変更する場合には以下の設定を行う。
メニューから を選択する
変更するユーザー欄の一番右のRoleを Admin や Editor に変更する
Dashboardへのアクセス権の設定¶
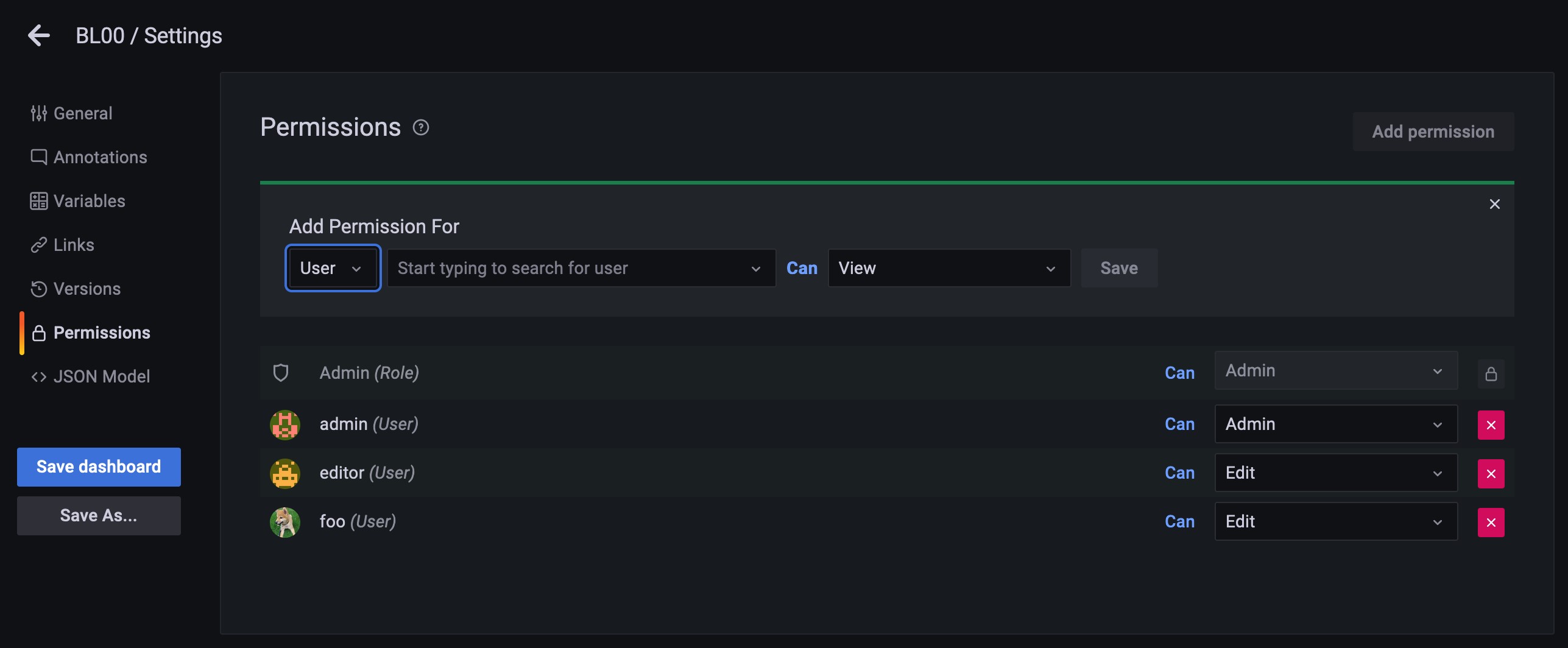
Fig. 320 Dashboardへのアクセス権設定画面¶
ブラウザからadminユーザーとしてGrafana Web UIへログインする
メニューから、 を選択し、アクセス権を追加するDashboardを選択する
画面右上の Dashboard settings を押下する
画面左のメニューから、 Permissions を選択する
Add Permissions for の下の選択肢を User に変更し、アクセス権を追加するユーザーを選び、アクセス権をView・Edit・Adminの中から選択して Save を押下する
Note
DashboardのデフォルトのPermissions設定では、権限を与える対象としてEditor(Role)とViewer(Role)が設定されており、 すべてのEditorおよびViewerのRoleを持つユーザーにその権限が与えられることになる。 特定のユーザーにのみこれらの権限を与えたい場合には、設定画面においてEditor(Role)やViewer(Role)を削除する必要がある。
Elasticsearchのデータ操作¶
Elasticsearchに保存されたデータを操作することが可能である。 ここでは使用されることが想定される操作について説明する。
インデックスの一覧表示¶
Elasticsearchに保存されているインデックスの一覧を表示することができる。 パスワードの設定 で設定したElasticsearchのパスワードが mlfadmin の場合、 以下のコマンドを実行する。
curl -XGET -u elastic:mlfadmin 'localhost:9200/_cat/indices?v'
インデックスの内容表示¶
Elasticsearchに保存されているインデックスのうち、任意のインデックスの内容を表示することができる。 例えば、インデックス logsurvsample-abc の内容を表示したい場合、以下のコマンドを実行する。
curl -XGET -u elastic:mlfadmin -H 'Content-Type:application/json' 'localhost:9200/logsurvsample-abc/_search?pretty'
応答はJSON形式で表示される。 デフォルトでは直近の10件分のデータ(ドキュメント)が表示されるため、リクエストにsizeパラメータを追加する。 直近の100件分のデータを表示する場合、以下のコマンドを実行する。
curl -XGET -u elastic:mlfadmin -H 'Content-Type:application/json' 'localhost:9200/logsurvsample-abc/_search?size=100&pretty'
また、指定した期間におけるデータを確認したい場合にはDate fieldを利用する。 例えば、2022年8月11日4:50から5:00までの期間についてデータを表示する場合、以下のコマンドを実行する (sizeパラメータを指定しない場合、10件分しか表示されない)。
curl -XGET -u elastic:mlfadmin -H 'Content-Type:application/json' 'localhost:9200/logsurvsample-abc/_doc/_search?size=10000&pretty' -d '{"query":{"range":{"Date":{"gte":"2022-08-11T04:50:00+09:00" , "lte":"2022-08-11T05:00:00+09:00"}}}}'
インデックスの削除¶
不要になったインデックスを削除することができる。 例えば、インデックス logsurvsample-abc を削除する場合、以下のコマンドを実行する。
curl -XDELETE -u elastic:mlfadmin -H 'Content-Type:application/json' 'localhost:9200/logsurvsample-abc?pretty=true'
削除に成功すると、以下のレスポンスが表示される。
{
"acknowledged": true
}
スクリプト¶
IROHA2.8.3以降、データ操作用のPythonスクリプトが util/elasticsearch/ に配置されている。
IROHA2.11の時点で使用できるスクリプトを以下に示す。
なお、すべてのスクリプトで共通の引数として、Elasticsearchの接続先、ユーザー情報を与える必要がある。
引数 |
デフォルト |
説明 |
|---|---|---|
--host |
localhost |
Elasticsearch接続先ホスト |
--port |
9200 |
Elasticsearch接続先ポート番号 |
--es_username |
elastic |
Elasticsearchユーザー名(環境変数 ES_USERNAME が設定されている場合はそちらが優先される) |
--es_password |
mlfadmin |
Elasticsearchユーザーパスワード(環境変数 ES_PASSWORD が設定されている場合はそちらが優先される) |
get_index_size.py¶
インデックスのサイズを表示するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
--total または -t |
(False) |
すべてのインデックスのサイズの合計を表示するかどうかを指定するフラグ。Falseの場合、保存されているすべてのインデックスについて、各インデックスのサイズを一覧で表示する。 |
ls_index.py¶
インデックスの情報を表示するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
--index_name |
(None) |
表示するインデックスを指定する。指定しない場合、保存されているすべてのインデックスについて、各インデックスの情報を一覧で表示する。 |
--doc_name |
(None) |
表示するドキュメントを指定する。--index_nameと組み合わせて使用する。 |
--date |
(None) |
指定した期間のドキュメントを指定する。形式は “206-04-01T09:00:00+09:00 2026-04-01T0910:00+09:00” のように、開始日時と終了日時をスペースで区切り指定する。指定しない場合、最も古いドキュメントから表示される。--index_name、 --doc_nameと組み合わせて使用する。 |
--size |
10 |
表示するドキュメントの数を指定する。 |
delete_index.py¶
インデックスを削除するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
index_name |
削除するインデックスを指定する。 |
ls_role.py¶
ElasticsearchのRoleを表示するスクリプト。共通の引数以外の引数は無い。
create_role.py¶
ElasticsearchのRoleを作成するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
role_type |
Roleの種別を指定する。書き込み用Roleの場合は “write”、読み取り専用Roleの場合は “read” を指定する。 |
|
role_name |
作成するRoleの名称を指定する。 |
|
index_name |
Roleに与えるインデックスを指定する。 |
delete_role.py¶
ElasticsearchのRoleを削除するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
role_name |
削除するRoleの名称を指定する。 |
ls_user.py¶
Elasticsearchのユーザーを表示するスクリプト。共通の引数以外の引数は無い。
create_user.py¶
Elasticsearchのユーザーを作成するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
user_name |
作成するユーザーのユーザー名を指定する。 |
|
password |
作成するユーザーのパスワードを指定する。 |
|
full_name |
作成するユーザーのフルネームを指定する。 |
|
role_name |
作成するユーザーに与えるRoleを指定する。 |
delete_user.py¶
Elasticsearchのユーザーを削除するスクリプト。
引数 |
デフォルト |
説明 |
|---|---|---|
user_name |
削除するユーザーのユーザー名を指定する。 |
Note
これらのスクリプトを実行する際には、必要なRoleを有するユーザーで実行する必要がある。